
In this tutorial, we’ll explore how to analyze large text datasets with LangChain and Python to find interesting data in anything from books to Wikipedia pages.
AI is such a big topic nowadays that OpenAI and libraries like LangChain barely need any introduction. Nevertheless, in case you’ve been lost in an alternate dimension for the past year or so, LangChain, in a nutshell, is a framework for developing applications powered by language models, allowing developers to use the power of LLMs and AI to analyze data and build their own AI apps.
Key Takeaways
In this piece, we’ll explore:
- Versatility of LangChain for Text Analysis: LangChain, integrated with language models like GPT-3.5, is a powerful tool for analyzing large text datasets. We’ll look atpractical applications like extracting data from lengthy documents, visualizing trends, and creating summaries.
- Technical Process and Examples: We’ll cover the technical process of using LangChain for text analysis. This includes splitting large texts into manageable chunks, using JSON for structured data output, and adjusting parameters like model temperature for optimal results.
- Advanced Techniques and Applications: Finally, we’ll delve into advanced text analysis techniques like text embeddings for associating text chunks and searching for relevant information in large datasets.
Use Cases
Before getting into all the technicalities, I think it’s nice to look at some use cases of text dataset analysis using LangChain. Here are some examples:
- Systematically extracting useful data from long documents.
- Visualizing trends within a text or text dataset.
- Making summaries for long and uninteresting texts.
Prerequisites
To follow along with this article, create a new folder and install LangChain and OpenAI using pip:
pip3 install langchain openai
File Reading, Text Splitting and Data Extraction
To analyze large texts, such as books, you need to split the texts into smaller chunks. This is because large texts, such as books, contain hundreds of thousands to millions of tokens, and considering that no LLM can process that many tokens at a time, there’s no way to analyze such texts as a whole without splitting.
Also, instead of saving individual prompt outputs for each chunk of a text, it’s more efficient to use a template for extracting data and putting it into a format like JSON or CSV.
In this tutorial, I’ll be using JSON. Here is the book that I’m using for this example, which I downloaded for free from Project Gutenberg. This code reads the book Beyond Good and Evil by Friedrich Nietzsche, splits it into chapters, makes a summary of the first chapter, extracts the philosophical messages, ethical theories and moral principles presented in the text, and puts it all into JSON format.
As you can see, I used the “gpt-3.5-turbo-1106” model to work with larger contexts of up to 16000 tokens and a 0.3 temperature to give it a bit of creativity. You can experiment with the temperature and see what works best with your use case.
Note: the temperature parameter determines the freedom of an LLM to make creative and sometimes random answers. The lower the temperature, the more factual the LLM output, and the higher the temperature, the more creative and random the LLM output.
The extracted data gets put into JSON format using create_structured_output_chain and the provided JSON schema:
json_schema = {
"type": "object",
"properties": {
"summary": {"title": "Summary", "description": "The chapter summary", "type": "string"},
"messages": {"title": "Messages", "description": "Philosophical messages", "type": "string"},
"ethics": {"title": "Ethics", "description": "Ethical theories and moral principles presented in the text", "type": "string"}
},
"required": ["summary", "messages", "ethics"],
}
chain = create_structured_output_chain(json_schema, llm, prompt, verbose=False)
The code then reads the text file containing the book and splits it by chapter. The chain is then given the first chapter of the book as text input:
f = open("texts/Beyond Good and Evil.txt", "r")
phi_text = str(f.read())
chapters = phi_text.split("CHAPTER")
print(chain.run(chapters[1]))
Here’s the output of the code:
{'summary': 'The chapter discusses the concept of utilitarianism and its application in ethical decision-making. It explores the idea of maximizing overall happiness and minimizing suffering as a moral principle. The chapter also delves into the criticisms of utilitarianism and the challenges of applying it in real-world scenarios.', 'messages': 'The chapter emphasizes the importance of considering the consequences of our actions and the well-being of all individuals affected. It encourages thoughtful and empathetic decision-making, taking into account the broader impact on society.', 'ethics': 'The ethical theories presented in the text include consequentialism, hedonistic utilitarianism, and the principle of the greatest good for the greatest number.'}
Pretty cool. Philosophical texts written 150 years ago are pretty hard to read and understand, but this code instantly translated the main points from the first chapter into an easy-to-understand report of the chapter’s summary, message and ethical theories/moral principles. The flowchart below will give you a visual representation of what happens in this code.
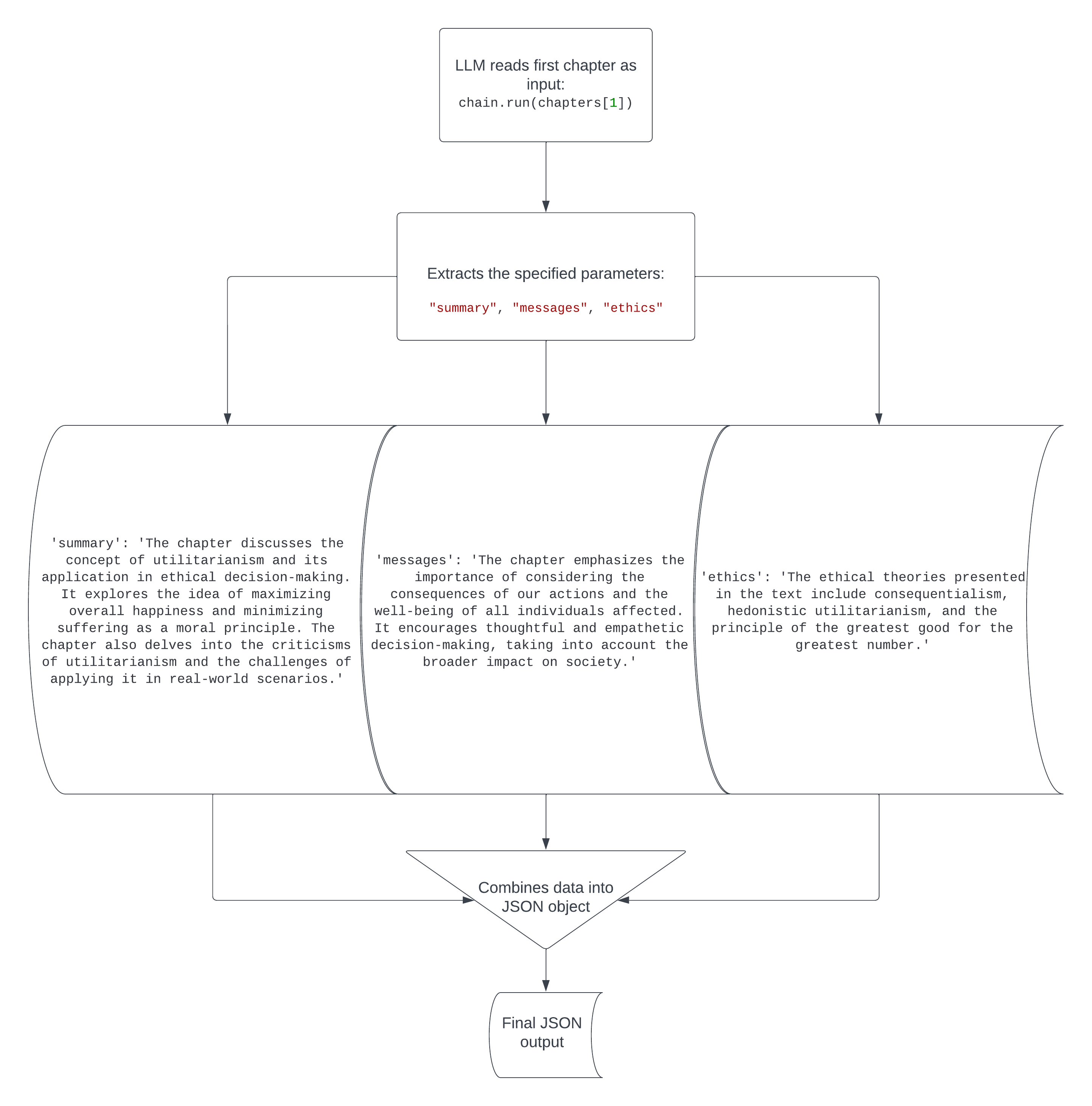
Now you can do the same for all the chapters and put everything into a JSON file using this code.
I added time.sleep(20) as comments, since it’s possible that you’ll hit rate limits when working with large texts, most likely if you have the free tier of the OpenAI API. Since I think it’s handy to know how many tokens and credits you’re using with your requests so as not to accidentally drain your account, I also used with get_openai_callback() as cb: to see how many tokens and credits are used for each chapter.
This is the part of the code that analyzes every chapter and puts the extracted data for each in a shared JSON file:
for chi in range(1, len(chapters), 1):
with get_openai_callback() as cb:
ch = chain.run(chapters[chi])
print(cb)
print("\n")
print(ch)
print("\n\n")
json_object = json.dumps(ch, indent=4)
if chi == 1:
with open("Beyond Good and Evil.json", "w") as outfile:
outfile.write("[\n"+json_object+",")
elif chi < len(chapters)-1:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+",")
else:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+"\n]")
The chi index starts at 1, because there’s no chapter 0 before chapter 1. If the chi index is 1 (on the first chapter), the code writes (overwrites any existing content) the JSON data to the file while also adding an opening square bracket and new line at the beginning, and a comma at the end to follow JSON syntax. If chi is not the minimum value (1) or maximum value (len(chapters)-1), the JSON data just gets added to the file along with a comma at the end. Finally, if chi is at its maximum value, the JSON gets added to the JSON file with a new line and closing square bracket.
After the code finishes running, you’ll see that Beyond Good and Evil.json is filled with the extracted info from all the chapters.
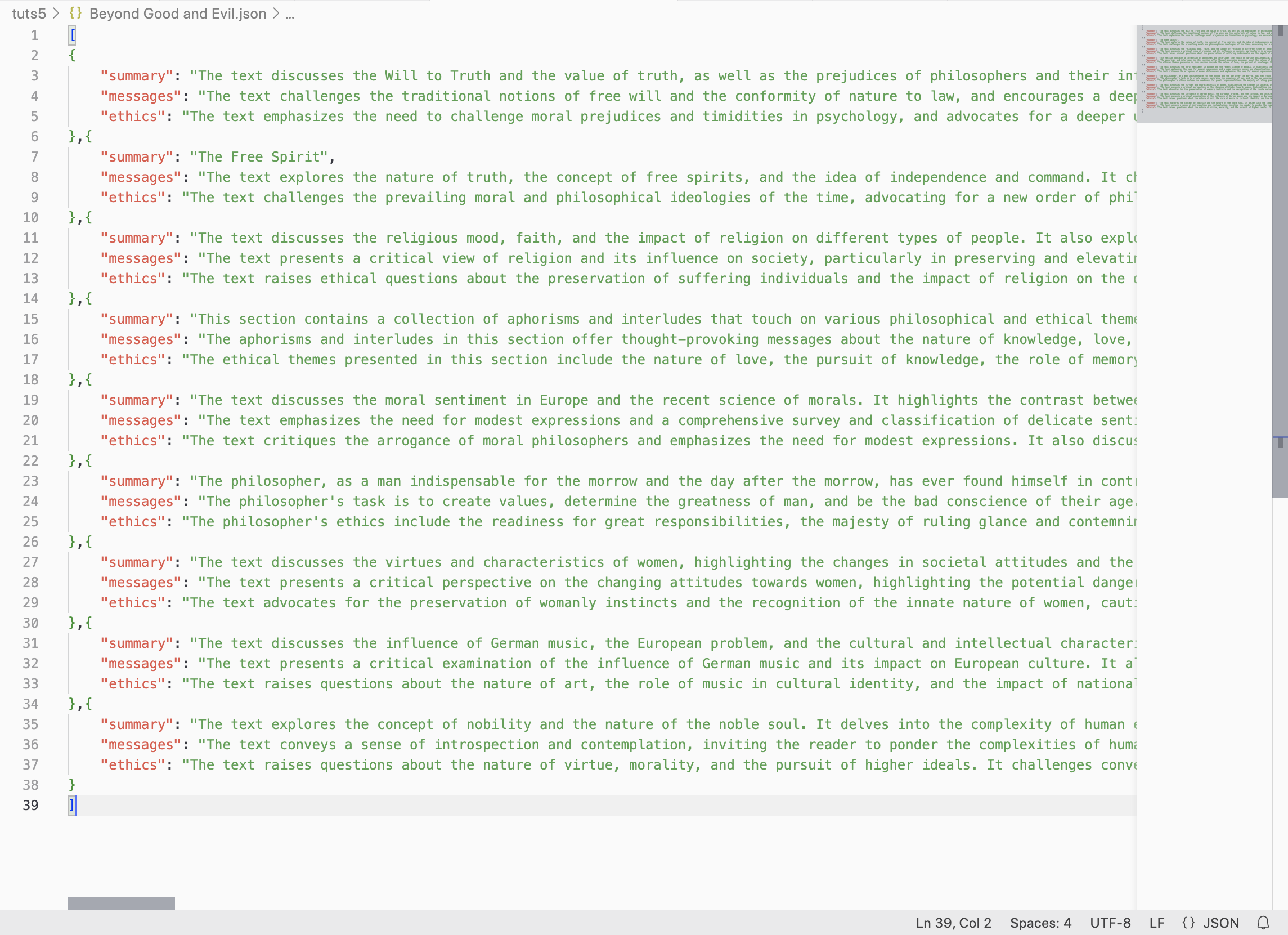
Here’s a visual representation of how this code works.
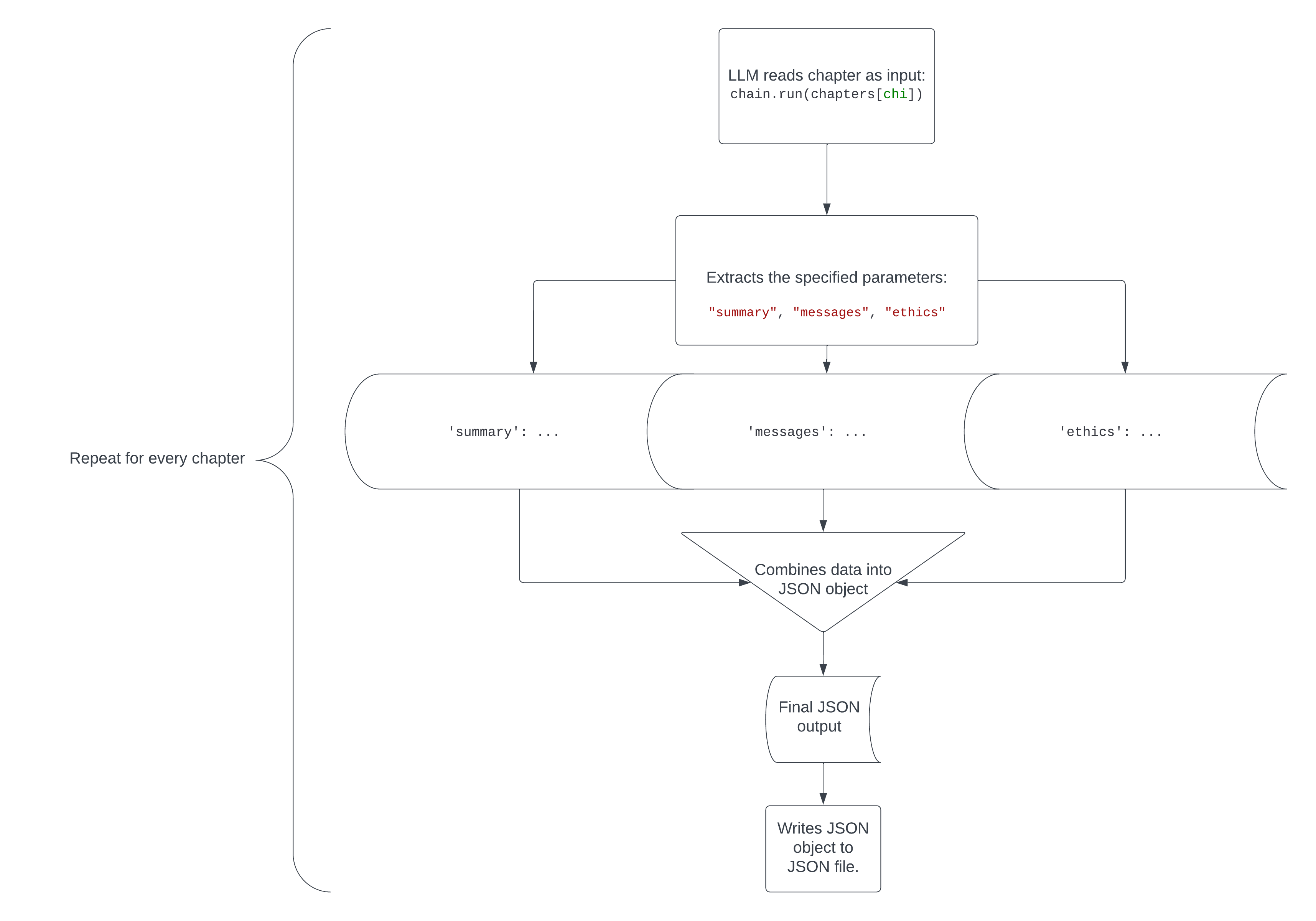
Working With Multiple Files
If you have dozens of separate files that you’d like to analyze one by one, you can use a script similar to the one you’ve just seen, but instead of iterating through chapters, it will iterate through files in a folder.
I’ll use the example of a folder filled with Wikipedia articles on the top 10 ranked tennis players (as of December 3 2023) called top_10_tennis_players. You can download the folder here. This code will read each Wikipedia article, extract each player’s age, height and fastest serve in km/h and put the extracted data into a JSON file in a separate folder called player_data.
Here’s an example of an extracted player data file.

However, this code isn’t that simple (I wish it was). To efficiently and reliably extract the most accurate data from texts that are often too big to analyze without chunk splitting, I used this code:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=16000,
chunk_overlap=2000,
length_function=len,
add_start_index=True,
)
sub_texts = text_splitter.create_documents([player_text])
ch = []
for ti in range(len(sub_texts)):
with get_openai_callback() as cb:
ch.append(chain.run(sub_texts[ti]))
print(ch[-1])
print(cb)
print("\n")
# time.sleep(10) if you hit rate limits
for chi in range(1, len(ch), 1):
if (ch[chi]["age"] > ch[0]["age"]) or (ch[0]["age"] == "not found" and ch[chi]["age"] != "not found"):
ch[0]["age"] = ch[chi]["age"]
break
if (ch[chi]["serve"] > ch[0]["serve"]) or (ch[0]["serve"] == "not found" and ch[chi]["serve"] != "not found"):
ch[0]["serve"] = ch[chi]["serve"]
break
if (ch[0]["height"] == "not found") and (ch[chi]["height"] != "not found"):
ch[0]["height"] = ch[chi]["height"]
break
else:
continue
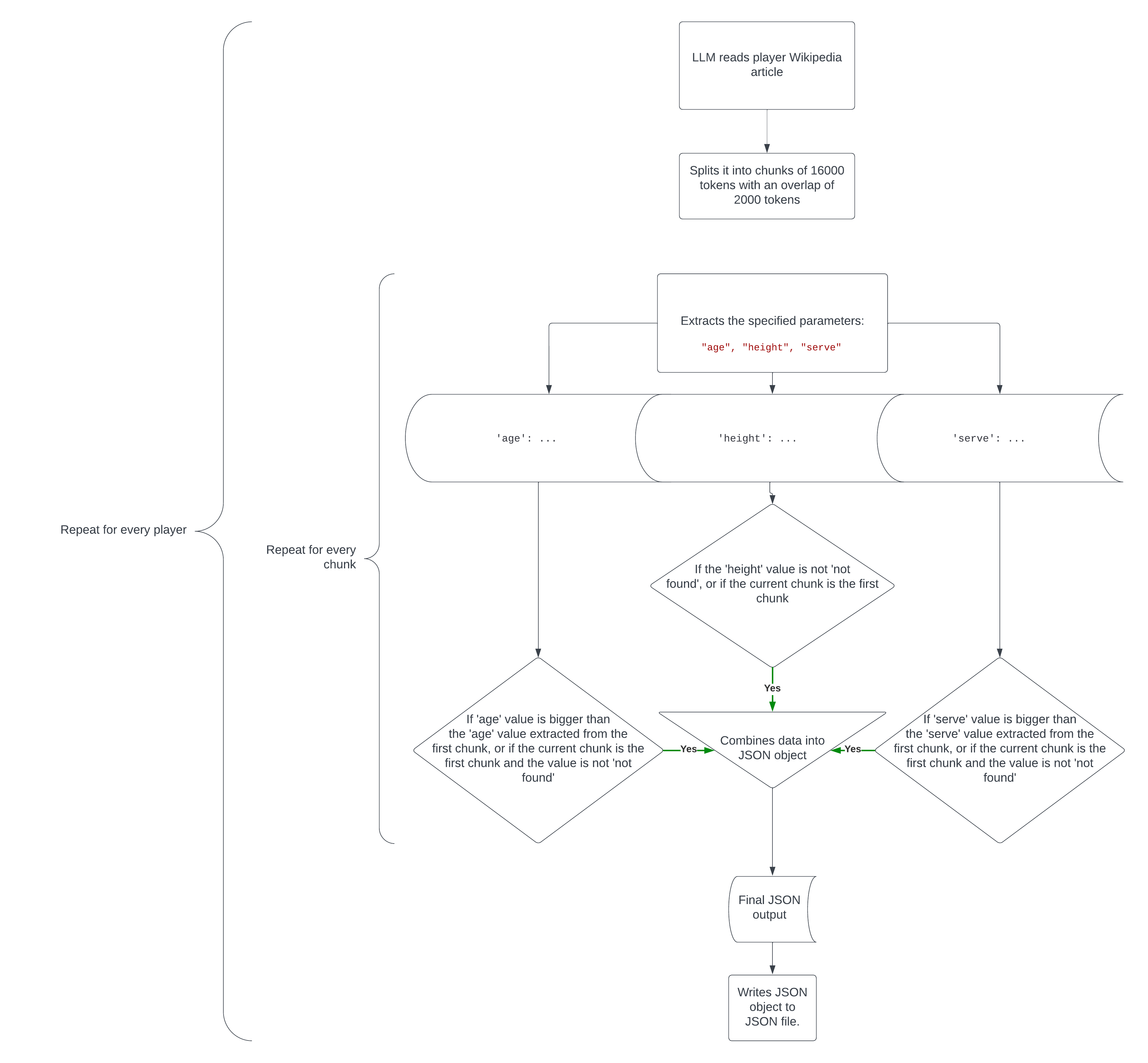
In essence, this code does the following:
- It splits the text into chunks 16000 tokens in size, with a chunk overlap of 2000 to keep a bit of context.
- it extracts the specified data from each chunk.
- If the data extracted from the latest chunk is more relevant or accurate than that of the first chunk (or the value isn’t found in the first chunk but is found in the latest chunk), it adjusts the values of the first chunk. For example, if chunk 1 says
'age': 26and chunk 2 says'age': 27, theagevalue will get updated to 27 since we need the player’s latest age, or if chunk 1 says'serve': 231and chunk 2 says'serve': 232, theservevalue will get updated to 232 since we’re looking for the fastest serve speed.
Here’s how the whole code works in a flowchart.
Text to Embeddings
Embeddings are vector lists that are used to associate pieces of text with each other.
A big aspect of text analysis in LangChain is searching large texts for specific chunks that are relevant to a certain input or question.
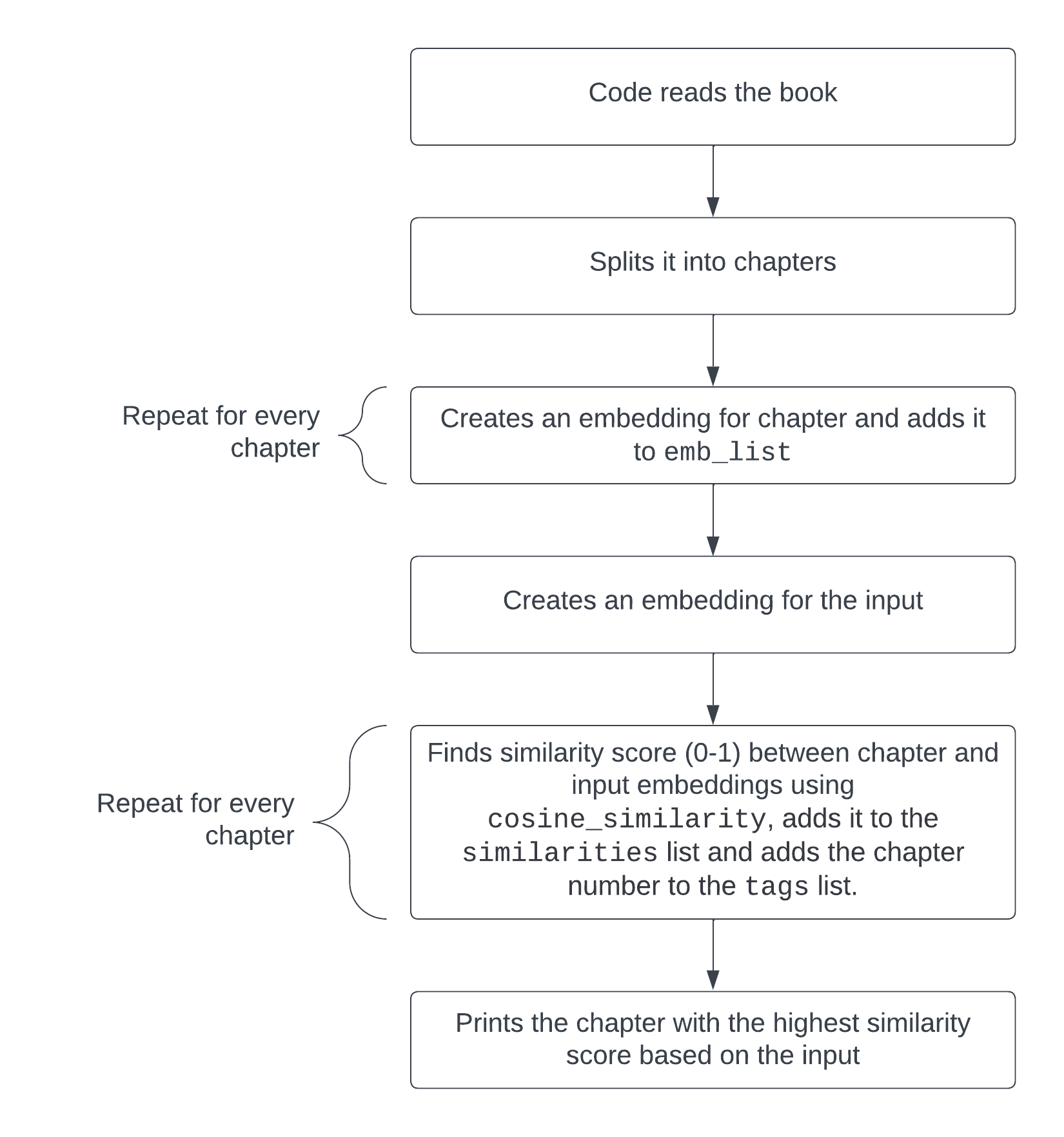
We can go back to the example with the Beyond Good and Evil book by Friedrich Nietzsche and make a simple script that takes a question on the text like “What are the flaws of philosophers?”, turns it into an embedding, splits the book into chapters, turns the different chapters into embeddings and finds the chapter most relevant to the inquiry, suggesting which chapter one should read to find an answer to this question as written by the author. You can find the code to do this here. This code in particular is what searches for the most relevant chapter for a given input or question:
embedded_question = embeddings_model.embed_query("What are the flaws of philosophers?")
similarities = []
tags = []
for i2 in range(len(emb_list)):
similarities.append(cosine_similarity(emb_list[i2], embedded_question))
tags.append(f"CHAPTER {i2}")
print(tags[similarities.index(max(similarities))])
The embeddings similarities between each chapter and the input get put into a list (similarities) and the number of each chapter gets put into the tags list. The most relevant chapter is then printed using print(tags[similarities.index(max(similarities))]), which gets the chapter number from the tags list that corresponds to the maximum value from the similarities list.
Output:
CHAPTER 1
Here’s how this code works visually.
Other Application Ideas
There are many other analytical uses for large texts with LangChain and LLMs, and even though they’re too complex to cover in this article in their entirety, I’ll list some of them and outline how they can be achieved in this section.
Visualizing topics
You can, for example, take transcripts of YouTube videos related to AI, like the ones in this dataset, extract the AI related tools mentioned in each video (LangChain, OpenAI, TensorFlow, and so on), compile them into a list, and find the overall most mentioned AI tools, or use a bar graph to visualize the popularity of each one.
Analyzing podcast transcripts
You can take podcast transcripts and, for example, find similarities and differences between the different guests in terms of their opinions and sentiment on a given topic. You can also make an embeddings script (like the one in this article) that searches the podcast transcripts for the most relevant conversations based on an input or question.
Analyzing evolutions of news articles
There are plenty of large news article datasets out there, like this one on BBC news headlines and descriptions and this one on financial news headlines and descriptions. Using such datasets, you can analyze things like sentiment, topics and keywords for each news article. You can then visualize how these aspects of the news articles evolve over time.
Conclusion
I hope you found this helpful and that you now have an idea of how to analyze large text datasets with LangChain in Python using different methods like embeddings and data extraction. Best of luck in your LangChain projects!
 Matt Nikonorov
Matt NikonorovI'm a full-stack developer with 3 years of experience with PHP, Python, Javascript and CSS. I love blogging about web development, application development and machine learning.








