
Asynchrony in any programming language is hard. Concepts like concurrency, parallelism, and deadlocks make even the most seasoned engineers shiver. Code that executes asynchronously is unpredictable and difficult to trace when there are bugs. The problem is inescapable because modern computing has multiple cores. There’s a thermal limit in each single core of the CPU, and nothing is getting any faster. This puts pressure on the developer to write efficient code that takes advantage of the hardware.
JavaScript is single-threaded, but does this limit Node from utilizing modern architecture? One of the biggest challenges is dealing with multiple threads because of its inherent complexity. Spinning up new threads and managing context switch in between is expensive. Both the operating system and the programmer must do a lot of work to deliver a solution that has many edge cases. In this take, I’ll show you how Node deals with this quagmire via the event loop. I’ll explore every part of the Node.js event loop and demonstrate how it works. One of the “killer app” features in Node is this loop, because it solved a hard problem in a radical new way.
What is the Event Loop?
The event loop is a single-threaded, non-blocking, and asynchronously concurrent loop. For those without a computer science degree, imagine a web request that does a database lookup. A single thread can only do one thing at a time. Instead of waiting on the database to respond, it continues to pick up other tasks in the queue. In the event loop, the main loop unwinds the call stack and doesn’t wait on callbacks. Because the loop doesn’t block, it’s free to work on more than one web request at a time. Multiple requests can get queued at the same time, which makes it concurrent. The loop doesn’t wait for everything from one request to complete, but picks up callbacks as they come without blocking.
The loop itself is semi-infinite, meaning if the call stack or the callback queue are empty it can exit the loop. Think of the call stack as synchronous code that unwinds, like console.log, before the loop polls for more work. Node uses libuv under the covers to poll the operating system for callbacks from incoming connections.
You may be wondering, why does the event loop execute in a single thread? Threads are relatively heavy in memory for the data it needs per connection. Threads are operating system resources that spin up, and this doesn’t scale to thousands of active connections.
Multiple threads in general also complicate the story. If a callback comes back with data, it must marshal context back to the executing thread. Context switching between threads is slow, because it must synchronize current state like the call stack or local variables. The event loop crushes bugs when multiple threads share resources, because it’s single-threaded. A single-threaded loop cuts thread-safety edge cases and can context switch much faster. This is the real genius behind the loop. It makes effective use of connections and threads while remaining scalable.
Enough theory; time to see what this looks like in code. Feel free to follow along in a REPL or download the source code.
Semi-infinite Loop
The biggest question the event loop must answer is whether the loop is alive. If so, it figures out how long to wait on the callback queue. At each iteration, the loop unwinds the call stack, then polls.
Here’s an example that blocks the main loop:
setTimeout(
() => console.log('Hi from the callback queue'),
5000); // Keep the loop alive for this long
const stopTime = Date.now() + 2000;
while (Date.now() < stopTime) {} // Block the main loop
If you run this code, note the loop gets blocked for two seconds. But the loop stays alive until the callback executes in five seconds. Once the main loop unblocks, the polling mechanism figures out how long it waits on callbacks. This loop dies when the call stack unwinds and there are no more callbacks left.
The Callback Queue
Now, what happens when I block the main loop and then schedule a callback? Once the loop gets blocked, it doesn’t put more callbacks on the queue:
const stopTime = Date.now() + 2000;
while (Date.now() < stopTime) {} // Block the main loop
// This takes 7 secs to execute
setTimeout(() => console.log('Ran callback A'), 5000);
This time the loop stays alive for seven seconds. The event loop is dumb in its simplicity. It has no way of knowing what might get queued in the future. In a real system, incoming callbacks get queued and execute as the main loop is free to poll. The event loop goes through several phases sequentially when it’s unblocked. So, to ace that job interview about the loop, avoid fancy jargon like “event emitter” or “reactor pattern”. It’s a humble single-threaded loop, concurrent, and non-blocking.
The Event Loop with async/await
To avoid blocking the main loop, one idea is to wrap synchronous I/O around async/await:
const fs = require('fs');
const readFileSync = async (path) => await fs.readFileSync(path);
readFileSync('readme.md').then((data) => console.log(data));
console.log('The event loop continues without blocking...');
Anything that comes after the await comes from the callback queue. The code reads like synchronously blocking code, but it doesn’t block. Note async/await makes readFileSync thenable, which takes it off the main loop. Think of anything that comes after await as non-blocking via a callback.
Full disclosure: the code above is for demonstration purposes only. In real code, I recommend fs.readFile, which fires a callback that can be wrapped around a promise. The general intent is still valid, because this takes blocking I/O off the main loop.
Taking It Further
What if I told you the event loop has more to it than the call stack and the callback queue? What if the event loop wasn’t just one loop but many? And what if it can have multiple threads under the covers?
Now, I want to take you behind the facade and into the fray of Node internals.
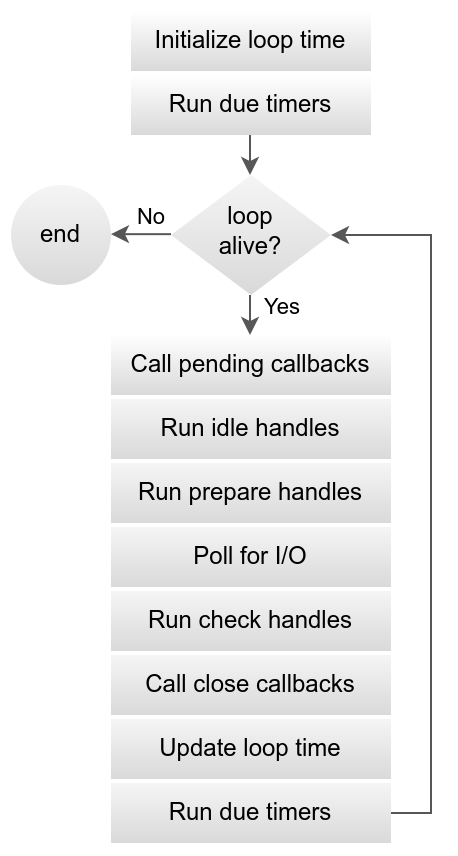
Event Loop Phases
These are the event loop phases:

Image source: libuv documentation
- Timestamps are updated. The event loop caches current time at the start of the loop to avoid frequent time-related system calls. These system calls are internal to libuv.
- Is the loop alive? If the loop has active handles, active requests, or closing handles, it’s alive. As shown, pending callbacks in the queue keep the loop alive.
- Due timers execute. This is where
setTimeoutorsetIntervalcallbacks run. The loop checks the cached now to have active callbacks that expired execute. - Pending callbacks in the queue execute. If the previous iteration deferred any callbacks, these run at this point. Polling typically runs I/O callbacks immediately, but there are exceptions. This step deals with any stragglers from the previous iteration.
- Idle handlers execute — mostly from poor naming, because these run at every iteration and are internal to libuv.
- Prepare handles for
setImmediatecallback execution within the loop iteration. These handles run before the loop blocks for I/O and prepares the queue for this callback type. - Calculate poll timeout. The loop must know how long it blocks for I/O. This is how it calculates the timeout:
- If the loop is about to exit, timeout is 0.
- If there are no active handles or requests, timeout is 0.
- If there are any idle handles, timeout is 0.
- If there are any handles pending in the queue, timeout is 0.
- If there are any closing handles, timeout is 0.
- If none of the above, the timeout is set to the closest timer, or if there are no active timers, infinity.
- The loop blocks for I/O with the duration from the previous phase. I/O related callbacks in the queue execute at this point.
- Check handle callbacks execute. This phase is where
setImmediateruns, and it’s the counterpart to preparing handles. AnysetImmediatecallbacks queued mid I/O callback execution run here. - Close callbacks execute. These are disposed active handles from closed connections.
- Iteration ends.
You might wonder why polling blocks for I/O when it’s supposed to be non-blocking? The loop only blocks when there are no pending callbacks in the queue and the call stack is empty. In Node, the closest timer can be set by setTimeout, for example. If set to infinity, the loop waits on incoming connections with more work. It’s a semi-infinite loop, because polling keeps the loop alive when there’s nothing left to do and there’s an active connection.
Here’s the Unix version of this timeout calculation in all its C glory:
int uv_backend_timeout(const uv_loop_t* loop) {
if (loop->stop_flag != 0)
return 0;
if (!uv__has_active_handles(loop) && !uv__has_active_reqs(loop))
return 0;
if (!QUEUE_EMPTY(&loop->idle_handles))
return 0;
if (!QUEUE_EMPTY(&loop->pending_queue))
return 0;
if (loop->closing_handles)
return 0;
return uv__next_timeout(loop);
}
You may not be too familiar with C, but this reads like English and does exactly what’s in phase seven.
A Phase-by-phase Demonstration
To show each phase in plain JavaScript:
// 1. Loop begins, timestamps are updated
const http = require('http');
// 2. The loop remains alive if there's code in the call stack to unwind
// 8. Poll for I/O and execute this callback from incoming connections
const server = http.createServer((req, res) => {
// Network I/O callback executes immediately after poll
res.end();
});
// Keep the loop alive if there is an open connection
// 7. If there's nothing left to do, calculate timeout
server.listen(8000);
const options = {
// Avoid a DNS lookup to stay out of the thread pool
hostname: '127.0.0.1',
port: 8000
};
const sendHttpRequest = () => {
// Network I/O callbacks run in phase 8
// File I/O callbacks run in phase 4
const req = http.request(options, () => {
console.log('Response received from the server');
// 9. Execute check handle callback
setImmediate(() =>
// 10. Close callback executes
server.close(() =>
// The End. SPOILER ALERT! The Loop dies at the end.
console.log('Closing the server')));
});
req.end();
};
// 3. Timer runs in 8 secs, meanwhile the loop is staying alive
// The timeout calculated before polling keeps it alive
setTimeout(() => sendHttpRequest(), 8000);
// 11. Iteration ends
Because file I/O callbacks run in phase four and before phase nine, expect setImmediate() to fire first:
fs.readFile('readme.md', () => {
setTimeout(() => console.log('File I/O callback via setTimeout()'), 0);
// This callback executes first
setImmediate(() => console.log('File I/O callback via setImmediate()'));
});
Network I/O without a DNS lookup is less expensive than file I/O, because it executes in the main event loop. File I/O instead gets queued via the thread pool. A DNS lookup uses the thread pool too, so this makes network I/O as expensive as file I/O.
The Thread Pool
Node internals have two main parts: the V8 JavaScript engine, and libuv. File I/O, DNS lookup, and network I/O happen via libuv.
This is the overall architecture:
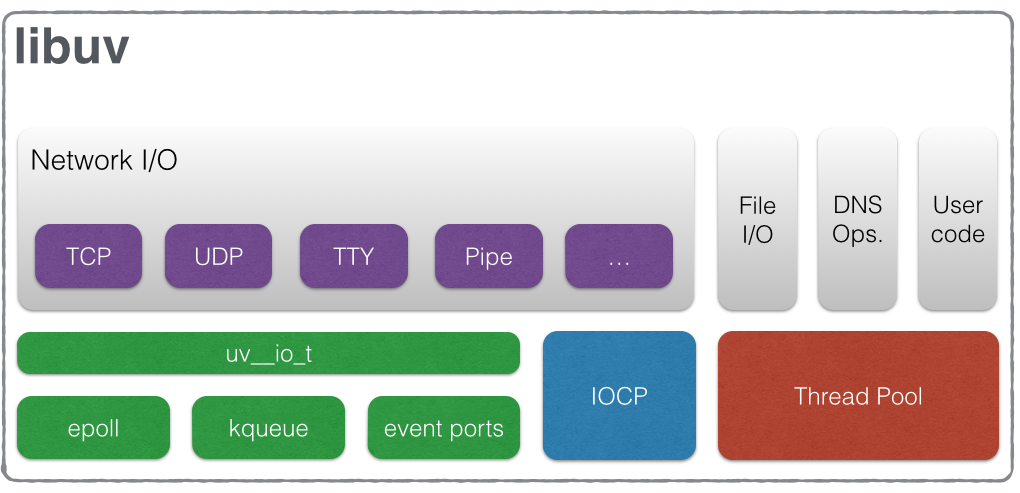
Image source: libuv documentation
For network I/O, the event loop polls inside the main thread. This thread is not thread-safe because it doesn’t context switch with another thread. File I/O and DNS lookup are platform-specific, so the approach is to run these in a thread pool. One idea is to do DNS lookup yourself to stay out of the thread pool, as shown in the code above. Putting in an IP address versus localhost, for example, takes the lookup out of the pool. The thread pool has a limited number of threads available, which can be set via the UV_THREADPOOL_SIZE environment variable. The default thread pool size is around four.
V8 executes in a separate loop, drains the call stack, then gives control back to the event loop. V8 can use multiple threads for garbage collection outside its own loop. Think of V8 as the engine that takes in raw JavaScript and runs it on the hardware.
To the average programmer, JavaScript remains single-threaded because there’s no thread-safety. V8 and libuv internals spin up their own separate threads to meet their own needs.
If there are throughput issues in Node, start with the main event loop. Check how long it takes the app to complete a single iteration. It should be no more than a hundred milliseconds. Then, check for thread pool starvation and what can be evicted out of the pool. It’s also possible to increase the size of the pool via the environment variable. The last step is to microbenchmark JavaScript code in V8 that executes synchronously.
Wrapping Up
The event loop continues to iterate through each phase as callbacks get queued. But, within each phase there’s a way to queue another type of callback.
process.nextTick() vs setImmediate()
At the end of each phase, the loop executes the process.nextTick() callback. Note that this callback type is not part of the event loop because it runs at the end of each phase. The setImmediate() callback is part of the overall event loop, so it’s not as immediate as the name implies. Because process.nextTick() needs intimate knowledge of the event loop, I recommend using setImmediate() in general.
There are a couple of reasons why you might need process.nextTick():
- Allow network I/O to handle errors, cleanup, or try the request again before the loop continues.
- It might be necessary to run a callback after the call stack unwinds but before the loop continues.
Say for example an event emitter wants to fire an event while still in its own constructor. The call stack must unwind first before calling the event.
const EventEmitter = require('events');
class ImpatientEmitter extends EventEmitter {
constructor() {
super();
// Fire this at the end of the phase with an unwound call stack
process.nextTick(() => this.emit('event'));
}
}
const emitter = new ImpatientEmitter();
emitter.on('event', () => console.log('An impatient event occurred!'));
Allowing the call stack to unwind can prevent errors like RangeError: Maximum call stack size exceeded. One gotcha is to make sure process.nextTick() doesn’t block the event loop. Blocking can be problematic with recursive callback calls within the same phase.
Conclusion
The event loop is simplicity in its ultimate sophistication. It takes a hard problem like asynchrony, thread-safety, and concurrency. It rips out what doesn’t help or what it doesn’t need and maximizes throughput in the most effective way possible. Because of this, Node programmers spend less time chasing asynchronous bugs and more time delivering new features.
FAQs About the Node.js Event Loop
The Node.js event loop is the core mechanism that allows Node.js to perform non-blocking, asynchronous operations. It’s responsible for handling I/O operations, timers, and callbacks in a single-threaded, event-driven environment.
The event loop continually checks the event queue for pending events or callbacks and executes them in the order they were added. It runs in a loop, handling events as they become available, which enables asynchronous programming in Node.js.
The event loop is at the heart of Node.js and ensures that applications remain responsive and can handle many simultaneous connections without the need for multiple threads.
The event loop in Node.js has several phases, including timers, pending callbacks, idle, poll, check, and close. These phases dictate how events are processed and in what order.
Common events include I/O operations (e.g., reading from a file or making a network request), timers (e.g., setTimeout and setInterval), and callback functions (e.g., callbacks from asynchronous operations).
Long-running CPU-bound operations can block the event loop and should be offloaded to child processes or worker threads using modules like child_process or the worker_threads module.
The call stack is a data structure that tracks function calls in the current execution context, while the event loop is responsible for managing asynchronous and non-blocking operations. They work together, as the event loop schedules the execution of callbacks and I/O operations, which are then pushed onto the call stack.
A “tick” refers to a single iteration of the event loop. During each tick, the event loop checks for pending events and executes any callbacks that are ready to run. Ticks are a fundamental unit of work in Node.js applications.
 Camilo Reyes
Camilo ReyesHusband, father, and software engineer from Houston, Texas. Passionate about JavaScript and cyber-ing all the things.





{kind=link}
{kind=link}